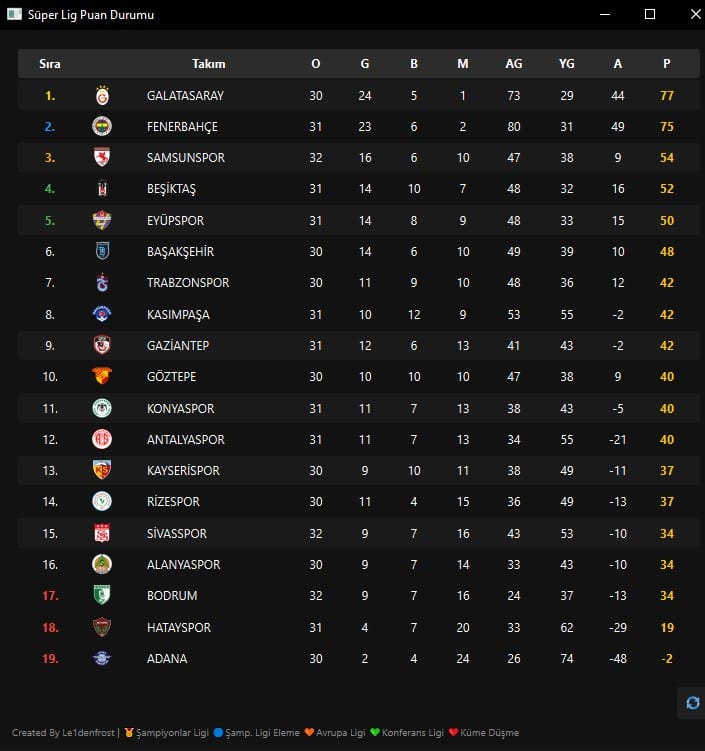
Nedir bu web scraping?
Kısaca internet sayfalarından ham HTML çekip, içinden işe yarar veriyi
ayıklama sanatıdır. Bir çeşit dijital madencilik düşün: HTTP isteğiyle
cevher (HTML) alırsın, BeautifulSoup’la öğütürsün, geriye temiz veri
kalır.
Bu yazıda tam da bu süreci uçtan uca deneyimleyeceğiz:
- İstek gönder → TFF’nin Süper Lig sayfasını içeri al.
- Ayrıştır →
table.s-tableiçindeki satırları, hücreleri sök. - Veriyi temizle → Sponsor eklerini at, sayı tiplerini düzelt.
- Sun → Pırıl pırıl tabloyu PyQt6 arayüzünde kullanıcıya göster.
Amaç, web scraping’in temel akışını gerçek bir projede görmek. “Hello World” değil, kullanılabilir bir uçtan uca örnek.
Kurulum ve ortam
Önce sanal ortamı kuralım ve bağımlılıkları yükleyelim:
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install requests beautifulsoup4 lxml PyQt6lxml’i BeautifulSoup için parser olarak kullanacağız çünkü Python’un
standart parser’ından belirgin biçimde hızlı. Büyük tablolar için fark
hissedilir.
HTTP isteği gönderme
requests ile minimum gürültülü bir istek atmak şöyle görünür.
User-Agent header’ı eklemek, bazı sitelerin varsayılan istekleri
reddetmesini önler:
import requests
from bs4 import BeautifulSoup
URL = "https://www.tff.org/Default.aspx?pageID=198"
HEADERS = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0 Safari/537.36"
)
}
response = requests.get(URL, headers=HEADERS, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, "lxml")HTML’i ayrıştırmak
BeautifulSoup’un en sevdiğim tarafı, CSS selektörlerini doğrudan
kullanabilmesi. soup.select() bir liste döner; ne bulamadığında patlar
ne de sessizce None döner:
rows = soup.select("table.s-table tbody tr")
teams = []
for row in rows:
cells = [c.get_text(strip=True) for c in row.select("td")]
if len(cells) < 9:
continue
teams.append({
"rank": int(cells[0]),
"name": cells[1],
"played": int(cells[2]),
"wins": int(cells[3]),
"draws": int(cells[4]),
"losses": int(cells[5]),
"gf": int(cells[6]),
"ga": int(cells[7]),
"points": int(cells[8]),
})Veriyi temizleme
Gerçek dünyada veri hiçbir zaman beklediğin gibi gelmez. Takım adlarına sponsor eki yapışmış olabilir, sayı sütunlarına bir tire karakteri kaçmış olabilir. Tek bir küçük normalize fonksiyonu hayat kurtarır:
SPONSOR_SUFFIXES = (" A.Ş.", " FK", " AŞ")
def clean_name(raw: str) -> str:
for suffix in SPONSOR_SUFFIXES:
if raw.endswith(suffix):
return raw[: -len(suffix)].strip()
return raw.strip()PyQt6 arayüzü
Veriyi terminale yazdırmak yerine küçük bir tablo penceresinde
gösterelim. PyQt6’nın QTableWidget’ı bu iş için fazlasıyla yeterli:
from PyQt6.QtWidgets import (
QApplication, QTableWidget, QTableWidgetItem
)
app = QApplication([])
table = QTableWidget(len(teams), 9)
table.setHorizontalHeaderLabels(
["#", "Takım", "O", "G", "B", "M", "AG", "YG", "P"]
)
for r, t in enumerate(teams):
for c, key in enumerate(["rank", "name", "played", "wins",
"draws", "losses", "gf", "ga", "points"]):
table.setItem(r, c, QTableWidgetItem(str(t[key])))
table.show()
app.exec()Kapanış notları
Web scraping’in tek satırlık örneklerden ibaret olmadığını görmek için kasıtlı olarak küçük ama uçtan uca bir akış seçtim. Gerçek projelerde karşına çıkacak şeyler aşağı yukarı bu akışın detaylandırılmış halinden ibaret.
Bir sonraki yazıda aynı pipeline’ı asenkron httpx ile dönüştürüp,
paralel istekle 10 sayfayı saniyeler içinde nasıl tarayacağımızı
göstereceğim.